Detailed Functionality¶
This document details the functionality provided by the SEM Python library, describing how to leverage all the available features. See the examples to see how the functionality described here can be used in practice, and refer to Command Line Interface for a primer on command-line interface features.
The simulation campaign paradigm¶
First of all: what do we mean with “simulation campaign”? Running a simulation
campaign means using an ns-3 simulation script to gather results (in the form of
output files and messages that are printed on the screen when the simulation is
run). The script may take various input parameters, that will influence the
results we obtain. In the following of this document, we will use the term
campaign as short for an instance of a sem.CampaignManager: this class
is the way SEM represents a campaign, with its script, parameters and results.
The sem.CampaignManager class collects a sem.DatabaseManager
and a sem.SimulationRunner, providing an higher-level interface to
simulation running and database management. All ‘major’ actions involving the
administration of a simulation campaign, such as running simulations with
precise parameter combinations, checking out the results and elaborating them
can be performed by interacting with a sem.CampaignManager object.
Obtaining a CampaignManager object¶
In order to obtain a simulation campaign, we must create a
sem.CampaignManager object, either by creating a new campaign through
the sem.CampaignManager.new() method or by loading it via
sem.CampaignManager.load(). Note that creating a campaign from scratch
requires you to specify an ns-3 installation path, whereas loading one doesn’t,
so that results from existing campaign can still be viewed without a working
ns-3 installation. Of course, an ns-3 installation must be specified if the
campaign object will also be used to run simulations.
Both campaign creation methods will, under the hood, create a
sem.DatabaseManager and a sem.SimulationRunner. The following
sections will briefly describe some implementation details of these classes.
Database management, briefly¶
SEM’s sem.DatabaseManager works with a folder, referred to as the
campaign_dir in the code, that contains a .json file and a data folder.
The .json file is a TinyDB database file, containing two tables: one for the
campaign information (namely the ns-3 script the campaign uses, its available
parameters and the hash of the commit at which the results were obtained), and
one containing dictionaries containing simulation results. This is an example of a result entry:
result = {
"meta": {
"elapsed_time": 0.12293100357055664,
"id": "241ec0ef-34b3-466f-9eb1-08b736b8afd5"
},
"params": {
"RngRun": 2,
"appPeriod": 600,
"nDevices": 100,
"radius": 5500,
"simulationTime": 600
}
}
The ‘meta’ entry contains information about the time needed to perform the simulation, and an unique id representing the simulation. The ‘params’ entry, instead, contains the parameters that were used to perform the simulation and their values. The id entry is used to link the database entry to a folder, inside the data folder, which contains all files generated by the simulation (i.e., the simulation output). The simulation results are saved separately from the database for practical reasons: copying the file over to the database is very expensive, and could inflate the database file’s size considerably and needlessly.
Results are typically added to the sem.DatabaseManager via the
sem.DatabaseManager.insert_result() by the campaign object after
simulations are run by a sem.SimulationRunner.
Simulation runners, briefly¶
The SimulationRunner class serves both as an
interface definition and as a simple implementation of the SEM component tasked
with running ns-3 simulations and, more in general, interfacing with the ns-3
installation. The most notable method provided by this class is
sem.SimulationRunner.run_simulations(), which takes a list of parameter
combination definitions, in the form of dictionaries, and runs those
simulations.
The ParallelRunner class takes the base methods
provided by SimulationRunner and overloads
sem.SimulationRunner.run_simulations(), leveraging multi-core systems to
perform parallel execution of simulations. Finally, the GridRunner class similarly overloads some methods, to leverage DRMAA
clusters for parallel execution of simulations.
Running simulations¶
As stated above, it’s not really necessary to know about
SimulationRunner to run simulations. This task
can be performed through the sem.CampaignManager interface, which
provides the sem.CampaignManager.run_missing_simulations() method. This
method takes either a list of parameter combinations or a dictionary specifying
a parameter space to explore, in the following form:
space = {
'param1': [value1, value2],
'param2': value3,
...
}
Note that if sem.CampaignManager.run_missing_simulations() is run twice
with the same parameters, it will only actually perform the simulations on the
first execution (i.e., it will only run the specified simulations that are
missing from the database): under the hood, the method checks among the
currently available results to see which parameter combinations are already
available, and only performs the ones that are not already in the database. As
soon as simulations finish, results are inserted in the database.
Results¶
Results can be accessed in two ways: either through the database manager or
through one of the export functions provided by sem.CampaignManager.
Getting single results¶
Single results can be accessed via
sem.DatabaseManager.get_complete_results(). This method will return a list
of dictionaries like the ones described in Database management, briefly, with an
additional ‘output’ field, containing a dictionary pairing each filename
generated by the simulation script with that output file’s contents. The method
accepts a params argument, consisting in a dictionary in which a query is
specified as described in Running simulations, with parameter keys and
corresponding values consisting in the desired parameter value or values,
specified as a python list.
To access a campaign’s DatabaseManager simply use the campaign object’s db member variable, and call the desired method:
campaign = CampaignManager.load('path/to/campaign')
results = campaign.db.get_complete_results()
Exporting results¶
sem.CampaignManager provides five main export methods:
The first two methods perform user-defined processing on the results and return them in a numpy or xarray structure, while the last three methods will save the results to an output format.
User-defined processing can be specified by passing a result-parsing function to the export functions, as shown in the scripts in the examples/ folder.
Class diagram¶
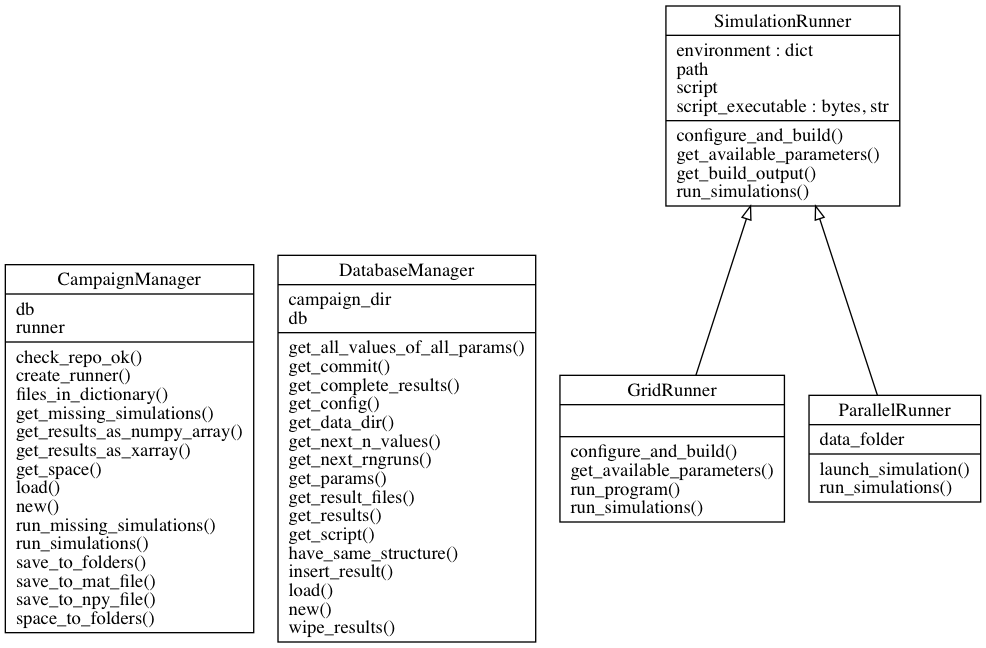
Class diagram for the SEM module.¶